
Have you ever been training a deep learning model for hours (or days or weeks) when it crashed, the power cut off, or you wanted to pause the training while you did something else?
Sure, you might be able to approximately figure out how to restart it manually (good luck). Don’t you wish deep learning training could be like putting your computer on sleep mode, or how a streaming service buffers the internet interruptions or remembers where you were in the movie when the power comes back on?
If you aren’t using cross-validation, you only need to add one line to your Keras model to take care of that, or a handful of lines if you need to handle something like k-fold cross-validation.
In the code below, the simple one-liner is in green near the bottom of this code, the key phrase being BackupAndRestore. By default, it will save your model and all the other variables needed to restart the model’s training state at the last epoch that was not finished. So when you rerun the code, it will automatically read that saved information and resume where you left off. The only required parameter is a directory location where to save those files in case of a stoppage. It will automatically clean up those files when it is done.
If each epoch takes a particularly long time, there is another parameter to BackupAndRestore so that you can restart every X number of batches (instead of waiting for all the batches of an epoch to finish.)
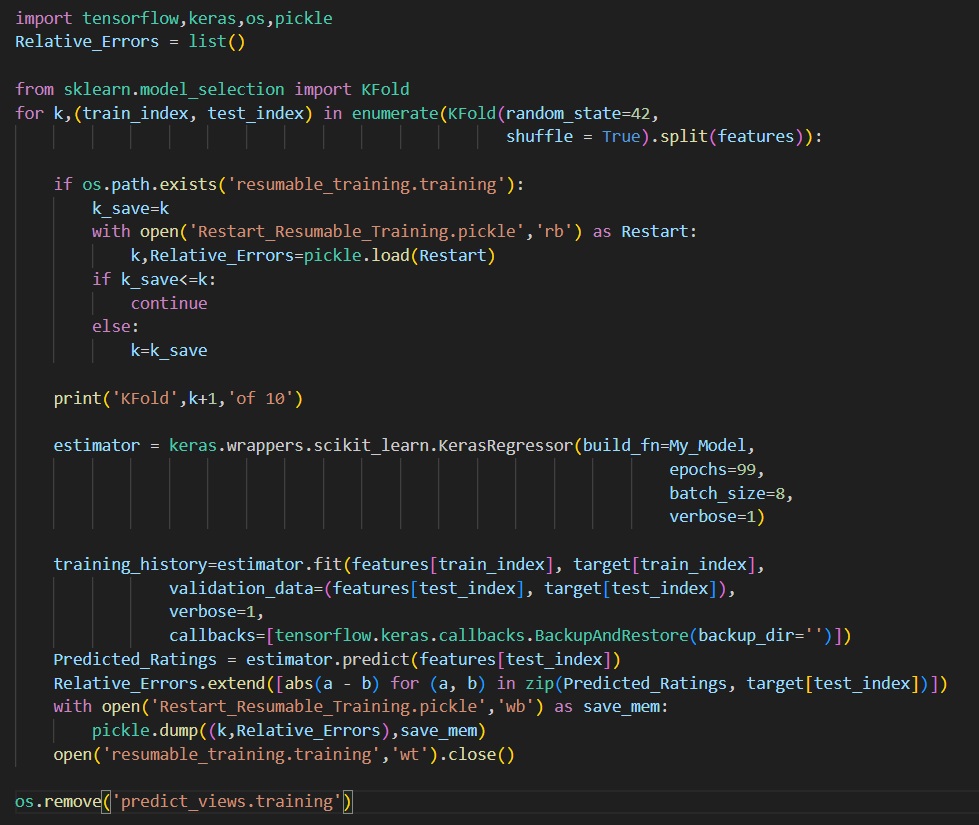
Since Google or SciKit-Learn has not given us a similar simple line of code to handle K-Fold cross-validation resumes, I added several lines to a normal training procedure to address that. The most important one is to remember which of the folds the program was running when it was stopped.
The save and load functions of the pickle class are used in the code above to have that information (stored in the variable k in the above code). I also stored and reloaded an additional variable I used to collect summary stats about each cross-validation iteration (i.e. the Relative_Errors list above). You may have your own data you want to save and restore or leave that out entirely.
Once you know which iteration of the cross-validation you last completed, you start it all over, but immediately skip to the next iteration until you get to the one that has not been finished. A semaphore file (in the code above, resumable_training.training) tells the program it has completed at least one k-fold cross-validation iteration (this file is deleted once the entire training has been completed). To make sure each partitioning of your data is the same upon resuming, the KFold parameter, random_state, is set to a hard-coded value. If you do not use the KFold parameter, shuffle=True, then you may not need to set random_state. Confirming that is an exercise left for the reader.
The code above is the simplest form of deep learning training with Keras. You will of course need to prepare your model and training data before running this code. If for any reason, that information could change between executions, then you need to make some similar pickle load/save code so that it is restored identically each time you run your program.
Now, feel free to crash your training runs as many times as you like, worry-free.
